Latent Semantic Analysis (LSA)
Latent Semantic Analysis
Latent Semantic Analysis (LSA) is a method that uses Singular Value Decomposition (SVD) to explore relationships between documents and their constituent words. Here, we will apply a simplified form of LSA to a subset of Yelp restaurant reviews.
The dataset, contained in “reviews limited vocab.txt”, includes 100,000 reviews from a training set, each review on a separate line. This dataset has been filtered to remove less common words, leaving a vocabulary of 1,731 words. From this data, we construct an n × d “document-term” matrix A, where “n” is the number of reviews (100,000) and “d” is the number of words in the vocabulary (1,731). Each element A_{i,j} in this matrix indicates how many times word “j” appears in review “i”.
In this matrix:
- Each row represents a different review, showing the frequency of each word in that review.
- Each column corresponds to a specific word from the vocabulary, indicating its frequency across all reviews.
However, in LSA, we don’t use the matrix A directly. Instead, we derive representations of reviews and words using a truncated SVD of A. This involves projecting columns of A onto a subspace formed by the left singular vectors of A that correspond to the “k” largest singular values, where “k” is a chosen parameter in LSA. This projection helps to reduce “noise” in the data, which might result from random occurrences of words in reviews.
An important application of LSA is to find words that are similar to a given word. This similarity is usually measured by the cosine similarity between their vector representations. Words are considered similar if their cosine similarity is high (close to 1) and dissimilar if it’s low (close to 0 or negative).
Import Libriries
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
Code Sinippet Provided in HW description
vocab = {}
vocab_size = 0
reviews = []
with open('reviews_limited_vocab.txt', 'r') as f:
for line in f.readlines():
words = line.strip().split(' ')
for word in words:
if word not in vocab:
vocab[word] = vocab_size
vocab_size += 1
reviews.append([vocab[word] for word in words])
invert_vocab = [''] * vocab_size
for (word, word_id) in vocab.items():
invert_vocab[word_id] = word
invert_vocab = np.array(invert_vocab)
words_to_compare = ['excellent', 'amazing', 'delicious', 'fantastic', 'gem', 'perfectly', 'incredible', 'worst', 'mediocre', 'bland', 'meh', 'awful', 'horrible', 'terrible']
k_to_try = [ 2, 4, 8 ]
Function Declarations
These are necessary functions to perform LSA
def create_document_term_matrix(reviews, vocab):
"""Function to create cocument term matrix A"""
# Initialize the document-term matrix A with zeros
A = np.zeros((len(reviews), len(vocab)))
# Construct the document-term matrix A
for i, review in enumerate(reviews):
for word_id in review:
A[i, word_id] += 1
return A
def cosine_similarity(v1, v2):
""" Function to compute cosine similarity between two vectors """
return np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2))
def cosine_similarity_matrix(vectors):
""" Function to calculate cosine similarity matrix """
n = vectors.shape[0]
similarity_matrix = np.zeros((n, n))
for i in range(vectors.shape[0]):
for j in range(i, vectors.shape[0]):
sim = cosine_similarity(vectors[i, :], vectors[j, :])
similarity_matrix[i, j] = sim
similarity_matrix[j, i] = sim # fill in the symmetric element
return similarity_matrix
def lsa_cosine_similarity_matrix(A, k_to_try, words_to_compare, vocab, invert_vocab, ignore_first_singular_value=False):
"""Function to apply LSA and compute the cosine similarity matrix for a given k"""
# Perform SVD on document-term matrix A
U, S, Vt = np.linalg.svd(A, full_matrices=False)
# To store all results
similarity_matrices = {}
# Trying different k
for k in k_to_try:
if ignore_first_singular_value:
# Ignore the first singular value by starting from the second one
S_k = S[1:k+1]
U_k = U[:, 1:k+1]
Vt_k = Vt[1:k+1, :]
else:
# Use the first k singular values
S_k = S[:k]
U_k = U[:, :k]
Vt_k = Vt[:k, :]
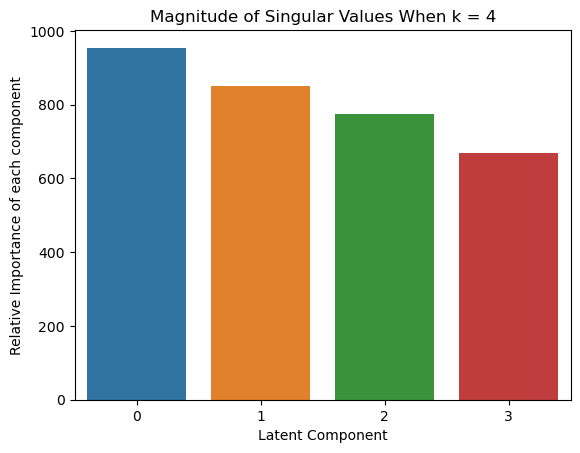
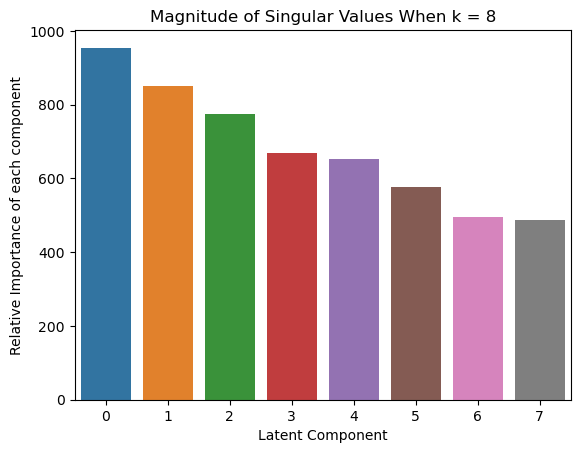
# Interesting Visualization: Visualize Singular values
sns.barplot(x=list(range(len(S_k))), y = S_k)
plt.xlabel('Latent Component') # Set the x-axis label
plt.ylabel('Relative Importance of each component') # Set the y-axis label
plt.title(f'Magnitude of Singular Values When k = {k}') # Set the title of the plot
plt.show() # Display the plot
# Get the word vectors from Vt
word_vectors = Vt_k.T
# Select the vectors corresponding to the words we want to compare
words_indices = [vocab[word] for word in words_to_compare]
selected_vectors = word_vectors[words_indices, :]
# Calculate the cosine similarity matrix for the selected word vectors
k_sim_matrix = cosine_similarity_matrix(selected_vectors)
similarity_matrices[k] = k_sim_matrix
return similarity_matrices
def display_similarity_matrix(similarity_matrix, words_to_compare):
""" Function to display a similarity matrix using pandas DataFrame """
# Create a DataFrame from the similarity matrix
df = pd.DataFrame(similarity_matrix, index=words_to_compare, columns=words_to_compare)
# Displaying df will make more prettier output, but only works on Jupyternotebook
display(df)
# For terminal, and more generally,
#print(df)
Constructing Document-term Matrix
We first construct the document term matrix A from the Yelp review data. For each value of $k$ in {2, 4, 8}, apply LSA with the given $k$, and then compute the cosine similarity between all pairs of words in the “words_to_compare” we declared above.
# Initialize document-term matrix A
A = create_document_term_matrix(reviews, vocab)
# Perform LSA for each k in k_to_try
# And show the magnitudes of singular values for each k
similarity_matrices = lsa_cosine_similarity_matrix(A, k_to_try, words_to_compare, vocab, invert_vocab)
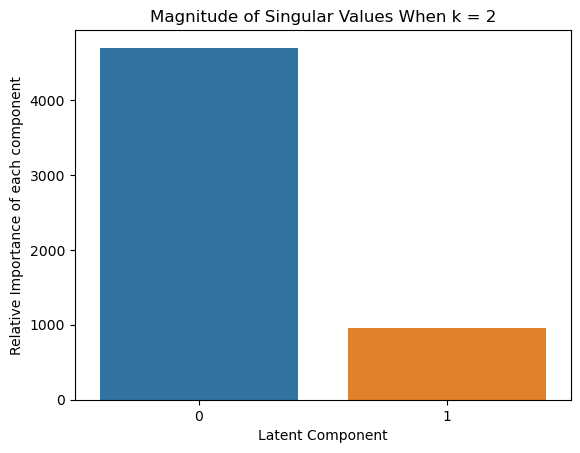
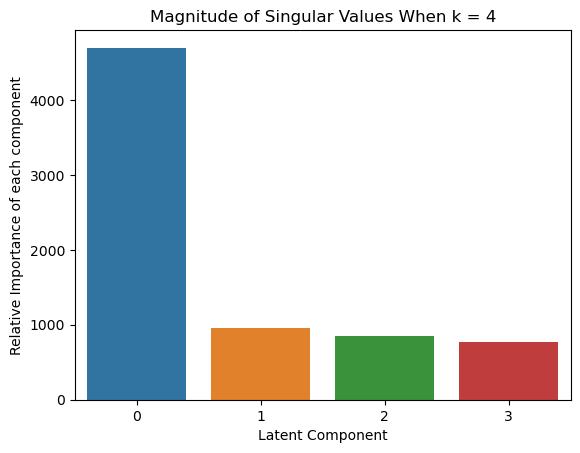
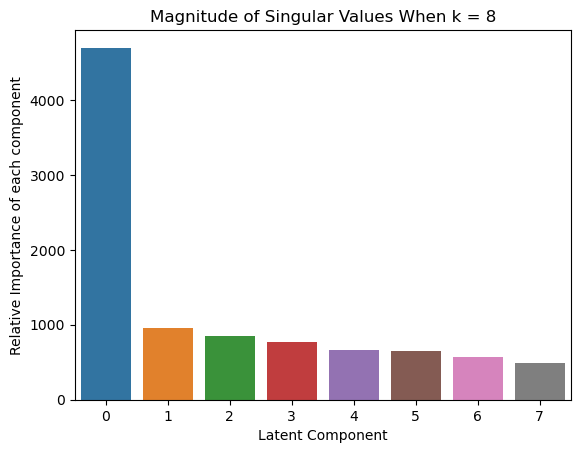
# Print out the tables
for k, matrix in similarity_matrices.items():
print()
print(f"Cosine Similarity Matrix for k={k}")
display_similarity_matrix(matrix, words_to_compare)
Cosine Similarity Matrix for k=2
| excellent | amazing | delicious | fantastic | gem | perfectly | incredible | worst | mediocre | bland | meh | awful | horrible | terrible | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| excellent | 1.000000 | 0.852972 | 0.849728 | 0.957973 | 0.966526 | 0.994959 | 0.982914 | 0.396789 | 0.587761 | 0.794862 | 0.129143 | 0.328731 | 0.243410 | 0.552588 |
| amazing | 0.852972 | 1.000000 | 0.999981 | 0.966852 | 0.958337 | 0.901014 | 0.934473 | 0.817559 | 0.923624 | 0.994713 | 0.627740 | 0.773346 | 0.713879 | 0.906369 |
| delicious | 0.849728 | 0.999981 | 1.000000 | 0.965254 | 0.956553 | 0.898314 | 0.932253 | 0.821104 | 0.925977 | 0.995329 | 0.632542 | 0.777252 | 0.718196 | 0.908964 |
| fantastic | 0.957973 | 0.966852 | 0.965254 | 1.000000 | 0.999505 | 0.981910 | 0.994406 | 0.643423 | 0.795137 | 0.935519 | 0.408171 | 0.585831 | 0.511410 | 0.768447 |
| gem | 0.966526 | 0.958337 | 0.956553 | 0.999505 | 1.000000 | 0.987383 | 0.997237 | 0.619013 | 0.775659 | 0.923938 | 0.379240 | 0.560036 | 0.484113 | 0.747929 |
| perfectly | 0.994959 | 0.901014 | 0.898314 | 0.981910 | 0.987383 | 1.000000 | 0.996417 | 0.486836 | 0.665928 | 0.851704 | 0.227931 | 0.421780 | 0.339446 | 0.633381 |
| incredible | 0.982914 | 0.934473 | 0.932253 | 0.994406 | 0.997237 | 0.996417 | 1.000000 | 0.558965 | 0.726634 | 0.892970 | 0.309460 | 0.496950 | 0.417780 | 0.696556 |
| worst | 0.396789 | 0.817559 | 0.821104 | 0.643423 | 0.619013 | 0.486836 | 0.558965 | 1.000000 | 0.975838 | 0.872371 | 0.961466 | 0.997333 | 0.986885 | 0.984297 |
| mediocre | 0.587761 | 0.923624 | 0.925977 | 0.795137 | 0.775659 | 0.665928 | 0.726634 | 0.975838 | 1.000000 | 0.958103 | 0.878165 | 0.957287 | 0.927768 | 0.999083 |
| bland | 0.794862 | 0.994713 | 0.995329 | 0.935519 | 0.923938 | 0.851704 | 0.892970 | 0.872371 | 0.958103 | 1.000000 | 0.704360 | 0.834363 | 0.782018 | 0.944963 |
| meh | 0.129143 | 0.627740 | 0.632542 | 0.408171 | 0.379240 | 0.227931 | 0.309460 | 0.961466 | 0.878165 | 0.704360 | 1.000000 | 0.978968 | 0.993236 | 0.897838 |
| awful | 0.328731 | 0.773346 | 0.777252 | 0.585831 | 0.560036 | 0.421780 | 0.496950 | 0.997333 | 0.957287 | 0.834363 | 0.978968 | 1.000000 | 0.996035 | 0.968787 |
| horrible | 0.243410 | 0.713879 | 0.718196 | 0.511410 | 0.484113 | 0.339446 | 0.417780 | 0.986885 | 0.927768 | 0.782018 | 0.993236 | 0.996035 | 1.000000 | 0.942893 |
| terrible | 0.552588 | 0.906369 | 0.908964 | 0.768447 | 0.747929 | 0.633381 | 0.696556 | 0.984297 | 0.999083 | 0.944963 | 0.897838 | 0.968787 | 0.942893 | 1.000000 |
Cosine Similarity Matrix for k=4
| excellent | amazing | delicious | fantastic | gem | perfectly | incredible | worst | mediocre | bland | meh | awful | horrible | terrible | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| excellent | 1.000000 | 0.838417 | 0.832617 | 0.877425 | 0.367586 | 0.899915 | 0.905511 | 0.238379 | 0.395601 | 0.339647 | 0.040934 | 0.218489 | 0.223238 | 0.388603 |
| amazing | 0.838417 | 1.000000 | 0.925742 | 0.920904 | 0.499862 | 0.753482 | 0.917296 | 0.342296 | 0.545550 | 0.333673 | 0.346251 | 0.296571 | 0.234892 | 0.400729 |
| delicious | 0.832617 | 0.925742 | 1.000000 | 0.888833 | 0.384616 | 0.739697 | 0.790877 | 0.420572 | 0.522929 | 0.307485 | 0.263357 | 0.444029 | 0.534012 | 0.659214 |
| fantastic | 0.877425 | 0.920904 | 0.888833 | 1.000000 | 0.715555 | 0.641796 | 0.951718 | 0.015855 | 0.206862 | 0.013009 | -0.045417 | 0.007949 | 0.110768 | 0.255955 |
| gem | 0.367586 | 0.499862 | 0.384616 | 0.715555 | 1.000000 | -0.031121 | 0.651108 | -0.620109 | -0.426191 | -0.623057 | -0.466367 | -0.628290 | -0.431861 | -0.368266 |
| perfectly | 0.899915 | 0.753482 | 0.739697 | 0.641796 | -0.031121 | 1.000000 | 0.730438 | 0.590659 | 0.713089 | 0.713688 | 0.392810 | 0.542778 | 0.378855 | 0.546352 |
| incredible | 0.905511 | 0.917296 | 0.790877 | 0.951718 | 0.651108 | 0.730438 | 1.000000 | 0.038360 | 0.283291 | 0.149389 | 0.041035 | -0.022526 | -0.064762 | 0.112853 |
| worst | 0.238379 | 0.342296 | 0.420572 | 0.015855 | -0.620109 | 0.590659 | 0.038360 | 1.000000 | 0.951259 | 0.918977 | 0.873191 | 0.981945 | 0.745096 | 0.802657 |
| mediocre | 0.395601 | 0.545550 | 0.522929 | 0.206862 | -0.426191 | 0.713089 | 0.283291 | 0.951259 | 1.000000 | 0.939858 | 0.915015 | 0.887203 | 0.569918 | 0.678875 |
| bland | 0.339647 | 0.333673 | 0.307485 | 0.013009 | -0.623057 | 0.713688 | 0.149389 | 0.918977 | 0.939858 | 1.000000 | 0.832056 | 0.845680 | 0.480877 | 0.580324 |
| meh | 0.040934 | 0.346251 | 0.263357 | -0.045417 | -0.466367 | 0.392810 | 0.041035 | 0.873191 | 0.915015 | 0.832056 | 1.000000 | 0.788501 | 0.410072 | 0.478992 |
| awful | 0.218489 | 0.296571 | 0.444029 | 0.007949 | -0.628290 | 0.542778 | -0.022526 | 0.981945 | 0.887203 | 0.845680 | 0.788501 | 1.000000 | 0.855481 | 0.889138 |
| horrible | 0.223238 | 0.234892 | 0.534012 | 0.110768 | -0.431861 | 0.378855 | -0.064762 | 0.745096 | 0.569918 | 0.480877 | 0.410072 | 0.855481 | 1.000000 | 0.980162 |
| terrible | 0.388603 | 0.400729 | 0.659214 | 0.255955 | -0.368266 | 0.546352 | 0.112853 | 0.802657 | 0.678875 | 0.580324 | 0.478992 | 0.889138 | 0.980162 | 1.000000 |
Cosine Similarity Matrix for k=8
| excellent | amazing | delicious | fantastic | gem | perfectly | incredible | worst | mediocre | bland | meh | awful | horrible | terrible | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| excellent | 1.000000 | 0.757212 | 0.913244 | 0.946878 | 0.642860 | 0.728462 | 0.886134 | -0.446355 | -0.245513 | 0.202035 | -0.057355 | -0.410635 | -0.285739 | -0.316515 |
| amazing | 0.757212 | 1.000000 | 0.885628 | 0.866461 | 0.461421 | 0.307658 | 0.801804 | -0.100694 | 0.008962 | 0.285970 | 0.116652 | -0.011437 | 0.145668 | 0.058541 |
| delicious | 0.913244 | 0.885628 | 1.000000 | 0.962863 | 0.595044 | 0.649186 | 0.867623 | -0.439328 | -0.174808 | 0.314393 | 0.103448 | -0.272696 | -0.178628 | -0.249375 |
| fantastic | 0.946878 | 0.866461 | 0.962863 | 1.000000 | 0.742615 | 0.580032 | 0.880537 | -0.456739 | -0.244197 | 0.155815 | 0.007043 | -0.401286 | -0.236362 | -0.284120 |
| gem | 0.642860 | 0.461421 | 0.595044 | 0.742615 | 1.000000 | 0.373033 | 0.686922 | -0.623148 | -0.535959 | -0.319720 | -0.265467 | -0.696574 | -0.508087 | -0.522608 |
| perfectly | 0.728462 | 0.307658 | 0.649186 | 0.580032 | 0.373033 | 1.000000 | 0.687379 | -0.648347 | -0.244231 | 0.418162 | 0.069499 | -0.388572 | -0.592331 | -0.600019 |
| incredible | 0.886134 | 0.801804 | 0.867623 | 0.880537 | 0.686922 | 0.687379 | 1.000000 | -0.404604 | -0.280858 | 0.167819 | -0.132857 | -0.317890 | -0.254532 | -0.325077 |
| worst | -0.446355 | -0.100694 | -0.439328 | -0.456739 | -0.623148 | -0.648347 | -0.404604 | 1.000000 | 0.640314 | 0.013827 | 0.075029 | 0.801343 | 0.898425 | 0.917839 |
| mediocre | -0.245513 | 0.008962 | -0.174808 | -0.244197 | -0.535959 | -0.244231 | -0.280858 | 0.640314 | 1.000000 | 0.679409 | 0.792349 | 0.855243 | 0.596824 | 0.715415 |
| bland | 0.202035 | 0.285970 | 0.314393 | 0.155815 | -0.319720 | 0.418162 | 0.167819 | 0.013827 | 0.679409 | 1.000000 | 0.851241 | 0.499588 | 0.078887 | 0.140180 |
| meh | -0.057355 | 0.116652 | 0.103448 | 0.007043 | -0.265467 | 0.069499 | -0.132857 | 0.075029 | 0.792349 | 0.851241 | 1.000000 | 0.504808 | 0.119485 | 0.235764 |
| awful | -0.410635 | -0.011437 | -0.272696 | -0.401286 | -0.696574 | -0.388572 | -0.317890 | 0.801343 | 0.855243 | 0.499588 | 0.504808 | 1.000000 | 0.834196 | 0.863486 |
| horrible | -0.285739 | 0.145668 | -0.178628 | -0.236362 | -0.508087 | -0.592331 | -0.254532 | 0.898425 | 0.596824 | 0.078887 | 0.119485 | 0.834196 | 1.000000 | 0.976510 |
| terrible | -0.316515 | 0.058541 | -0.249375 | -0.284120 | -0.522608 | -0.600019 | -0.325077 | 0.917839 | 0.715415 | 0.140180 | 0.235764 | 0.863486 | 0.976510 | 1.000000 |
Improving by Ignoring the Largest Singular Value
Sometimes LSA can be improved by ignoring the direction corresponding to the largest singular value. Otherwise, we repeat the previous step
# Now for Problem 6, repeat the process from Problem 5, but ignoring the first singular value
similarity_matrices_ignore_first = lsa_cosine_similarity_matrix(A, k_to_try, words_to_compare, vocab, invert_vocab, ignore_first_singular_value=True)
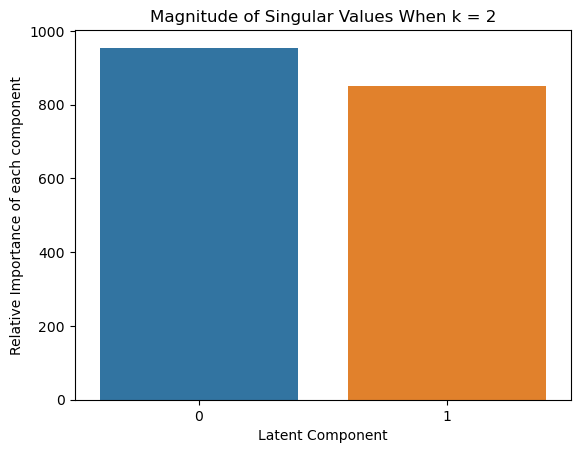
# Repeat the process from Problem 5, for the matrices where the first singular value is ignored
for k, matrix in similarity_matrices_ignore_first.items():
print(f"Cosine Similarity Matrix ignoring first singular value for k={k}")
display_similarity_matrix(matrix, words_to_compare)
Cosine Similarity Matrix ignoring first singular value for k=2
| excellent | amazing | delicious | fantastic | gem | perfectly | incredible | worst | mediocre | bland | meh | awful | horrible | terrible | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| excellent | 1.000000 | 0.940112 | 0.978348 | 0.853661 | 0.210705 | 0.911815 | 0.871880 | -0.037405 | 0.141824 | 0.297500 | -0.501481 | -0.064247 | -0.077675 | 0.087554 |
| amazing | 0.940112 | 1.000000 | 0.849209 | 0.980070 | 0.531301 | 0.717247 | 0.986594 | -0.375793 | -0.204091 | -0.045750 | -0.766356 | -0.400562 | -0.412861 | -0.257247 |
| delicious | 0.978348 | 0.849209 | 1.000000 | 0.727385 | 0.003825 | 0.977053 | 0.751647 | 0.170225 | 0.343626 | 0.488652 | -0.311564 | 0.143681 | 0.130346 | 0.291829 |
| fantastic | 0.853661 | 0.980070 | 0.727385 | 1.000000 | 0.689007 | 0.564528 | 0.999350 | -0.552396 | -0.394495 | -0.243283 | -0.878700 | -0.574598 | -0.585564 | -0.444087 |
| gem | 0.210705 | 0.531301 | 0.003825 | 0.689007 | 1.000000 | -0.209259 | 0.662436 | -0.984747 | -0.937785 | -0.870603 | -0.951410 | -0.989067 | -0.990963 | -0.955347 |
| perfectly | 0.911815 | 0.717247 | 0.977053 | 0.564528 | -0.209259 | 1.000000 | 0.593913 | 0.376208 | 0.535768 | 0.663275 | -0.102018 | 0.351172 | 0.338536 | 0.488858 |
| incredible | 0.871880 | 0.986594 | 0.751647 | 0.999350 | 0.662436 | 0.593913 | 1.000000 | -0.521990 | -0.361117 | -0.208163 | -0.860922 | -0.544724 | -0.555964 | -0.411502 |
| worst | -0.037405 | -0.375793 | 0.170225 | -0.552396 | -0.984747 | 0.376208 | -0.521990 | 1.000000 | 0.983894 | 0.942926 | 0.883321 | 0.999639 | 0.999186 | 0.992188 |
| mediocre | 0.141824 | -0.204091 | 0.343626 | -0.394495 | -0.937785 | 0.535768 | -0.361117 | 0.983894 | 1.000000 | 0.987264 | 0.785301 | 0.978735 | 0.975885 | 0.998508 |
| bland | 0.297500 | -0.045750 | 0.488652 | -0.243283 | -0.870603 | 0.663275 | -0.208163 | 0.942926 | 0.987264 | 1.000000 | 0.676805 | 0.933636 | 0.928729 | 0.977103 |
| meh | -0.501481 | -0.766356 | -0.311564 | -0.878700 | -0.951410 | -0.102018 | -0.860922 | 0.883321 | 0.785301 | 0.676805 | 1.000000 | 0.895600 | 0.901507 | 0.817939 |
| awful | -0.064247 | -0.400562 | 0.143681 | -0.574598 | -0.989067 | 0.351172 | -0.544724 | 0.999639 | 0.978735 | 0.933636 | 0.895600 | 1.000000 | 0.999909 | 0.988477 |
| horrible | -0.077675 | -0.412861 | 0.130346 | -0.585564 | -0.990963 | 0.338536 | -0.555964 | 0.999186 | 0.975885 | 0.928729 | 0.901507 | 0.999909 | 1.000000 | 0.986349 |
| terrible | 0.087554 | -0.257247 | 0.291829 | -0.444087 | -0.955347 | 0.488858 | -0.411502 | 0.992188 | 0.998508 | 0.977103 | 0.817939 | 0.988477 | 0.986349 | 1.000000 |
Cosine Similarity Matrix ignoring first singular value for k=4
| excellent | amazing | delicious | fantastic | gem | perfectly | incredible | worst | mediocre | bland | meh | awful | horrible | terrible | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| excellent | 1.000000 | 0.952511 | 0.927426 | 0.949991 | 0.600398 | 0.957977 | 0.958607 | -0.792342 | -0.619188 | 0.401247 | -0.152142 | -0.699292 | -0.689470 | -0.687167 |
| amazing | 0.952511 | 1.000000 | 0.979118 | 0.985011 | 0.686898 | 0.943633 | 0.949524 | -0.929325 | -0.770642 | 0.338148 | -0.076859 | -0.840224 | -0.834480 | -0.850561 |
| delicious | 0.927426 | 0.979118 | 1.000000 | 0.964047 | 0.615095 | 0.933615 | 0.881725 | -0.896924 | -0.748275 | 0.355308 | -0.044969 | -0.766005 | -0.736131 | -0.771511 |
| fantastic | 0.949991 | 0.985011 | 0.964047 | 1.000000 | 0.776727 | 0.893334 | 0.964140 | -0.935094 | -0.830149 | 0.193120 | -0.245969 | -0.864644 | -0.805914 | -0.820088 |
| gem | 0.600398 | 0.686898 | 0.615095 | 0.776727 | 1.000000 | 0.428507 | 0.771553 | -0.839107 | -0.940355 | -0.426393 | -0.654373 | -0.918491 | -0.754277 | -0.749785 |
| perfectly | 0.957977 | 0.943633 | 0.933615 | 0.893334 | 0.428507 | 1.000000 | 0.881865 | -0.763050 | -0.517256 | 0.611104 | 0.133591 | -0.630926 | -0.696013 | -0.705159 |
| incredible | 0.958607 | 0.949524 | 0.881725 | 0.964140 | 0.771553 | 0.881865 | 1.000000 | -0.872983 | -0.746083 | 0.217615 | -0.273820 | -0.846616 | -0.824180 | -0.809089 |
| worst | -0.792342 | -0.929325 | -0.896924 | -0.935094 | -0.839107 | -0.763050 | -0.872983 | 1.000000 | 0.932621 | -0.054413 | 0.183163 | 0.965789 | 0.917141 | 0.941963 |
| mediocre | -0.619188 | -0.770642 | -0.748275 | -0.830149 | -0.940355 | -0.517256 | -0.746083 | 0.932621 | 1.000000 | 0.301769 | 0.455950 | 0.944274 | 0.794027 | 0.823833 |
| bland | 0.401247 | 0.338148 | 0.355308 | 0.193120 | -0.426393 | 0.611104 | 0.217615 | -0.054413 | 0.301769 | 1.000000 | 0.777166 | 0.112555 | -0.142947 | -0.143978 |
| meh | -0.152142 | -0.076859 | -0.044969 | -0.245969 | -0.654373 | 0.133591 | -0.273820 | 0.183163 | 0.455950 | 0.777166 | 1.000000 | 0.302955 | 0.017012 | -0.005956 |
| awful | -0.699292 | -0.840224 | -0.766005 | -0.864644 | -0.918491 | -0.630926 | -0.846616 | 0.965789 | 0.944274 | 0.112555 | 0.302955 | 1.000000 | 0.944061 | 0.949244 |
| horrible | -0.689470 | -0.834480 | -0.736131 | -0.805914 | -0.754277 | -0.696013 | -0.824180 | 0.917141 | 0.794027 | -0.142947 | 0.017012 | 0.944061 | 1.000000 | 0.993956 |
| terrible | -0.687167 | -0.850561 | -0.771511 | -0.820088 | -0.749785 | -0.705159 | -0.809089 | 0.941963 | 0.823833 | -0.143978 | -0.005956 | 0.949244 | 0.993956 | 1.000000 |
Cosine Similarity Matrix ignoring first singular value for k=8
| excellent | amazing | delicious | fantastic | gem | perfectly | incredible | worst | mediocre | bland | meh | awful | horrible | terrible | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| excellent | 1.000000 | 0.825902 | 0.804167 | 0.959289 | 0.764380 | 0.426687 | 0.830271 | -0.348296 | 0.161682 | 0.238291 | -0.032080 | -0.222790 | 0.026182 | 0.005882 |
| amazing | 0.825902 | 1.000000 | 0.823278 | 0.900467 | 0.614963 | 0.115254 | 0.786415 | -0.088094 | 0.270989 | 0.302473 | 0.103273 | 0.067038 | 0.310632 | 0.240466 |
| delicious | 0.804167 | 0.823278 | 1.000000 | 0.884065 | 0.566796 | 0.563780 | 0.855699 | -0.522318 | -0.145022 | 0.279013 | 0.036923 | -0.320334 | -0.140033 | -0.220939 |
| fantastic | 0.959289 | 0.900467 | 0.884065 | 1.000000 | 0.819723 | 0.346943 | 0.850093 | -0.401065 | 0.092409 | 0.186666 | 0.003272 | -0.267488 | 0.012609 | -0.026147 |
| gem | 0.764380 | 0.614963 | 0.566796 | 0.819723 | 1.000000 | 0.171534 | 0.691531 | -0.505794 | -0.067471 | -0.191903 | -0.204276 | -0.473570 | -0.167153 | -0.174568 |
| perfectly | 0.426687 | 0.115254 | 0.563780 | 0.346943 | 0.171534 | 1.000000 | 0.569491 | -0.767211 | -0.415155 | 0.320437 | -0.033403 | -0.518119 | -0.674398 | -0.701069 |
| incredible | 0.830271 | 0.786415 | 0.855699 | 0.850093 | 0.691531 | 0.569491 | 1.000000 | -0.490503 | -0.199292 | 0.127180 | -0.223340 | -0.359359 | -0.181406 | -0.263427 |
| worst | -0.348296 | -0.088094 | -0.522318 | -0.401065 | -0.505794 | -0.767211 | -0.490503 | 1.000000 | 0.541594 | -0.030733 | 0.021576 | 0.785444 | 0.853108 | 0.861272 |
| mediocre | 0.161682 | 0.270989 | -0.145022 | 0.092409 | -0.067471 | -0.415155 | -0.199292 | 0.541594 | 1.000000 | 0.624990 | 0.675774 | 0.798432 | 0.677179 | 0.765852 |
| bland | 0.238291 | 0.302473 | 0.279013 | 0.186666 | -0.191903 | 0.320437 | 0.127180 | -0.030733 | 0.624990 | 1.000000 | 0.839319 | 0.488788 | 0.119103 | 0.166041 |
| meh | -0.032080 | 0.103273 | 0.036923 | 0.003272 | -0.204276 | -0.033403 | -0.223340 | 0.021576 | 0.675774 | 0.839319 | 1.000000 | 0.477533 | 0.120404 | 0.218177 |
| awful | -0.222790 | 0.067038 | -0.320334 | -0.267488 | -0.473570 | -0.518119 | -0.359359 | 0.785444 | 0.798432 | 0.488788 | 0.477533 | 1.000000 | 0.835591 | 0.854364 |
| horrible | 0.026182 | 0.310632 | -0.140033 | 0.012609 | -0.167153 | -0.674398 | -0.181406 | 0.853108 | 0.677179 | 0.119103 | 0.120404 | 0.835591 | 1.000000 | 0.981254 |
| terrible | 0.005882 | 0.240466 | -0.220939 | -0.026147 | -0.174568 | -0.701069 | -0.263427 | 0.861272 | 0.765852 | 0.166041 | 0.218177 | 0.854364 | 0.981254 | 1.000000 |
Observation
By ignoring the direction corresponding to the largest singular value, we do see some improvement. Difference between cosine similarities seem more distinict with smaller $k$.
Leave a comment