Fake News Classification
“Fake News”—is one of the defining features of contemporary democratic life.
In this Blog Post, we will develop and assess a fake news classifier using Tensorflow.
Note: Working on this Blog Post in Google Colab is highly recommended.
Import
import nltk
from nltk.corpus import stopwords
nltk.download('stopwords')
import numpy as np
import pandas as pd
import re
import string
from matplotlib import pyplot as plt
import plotly.express as px
import plotly.io as pio
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, losses, utils
from tensorflow.keras.layers.experimental.preprocessing import TextVectorization
from sklearn.decomposition import PCA
[nltk_data] Downloading package stopwords to /root/nltk_data...
[nltk_data] Unzipping corpora/stopwords.zip.
Acquire Training Data
train_url = "https://github.com/PhilChodrow/PIC16b/blob/master/datasets/fake_news_train.csv?raw=true"
raw_df = pd.read_csv(train_url)
raw_df.head()
| Unnamed: 0 | title | text | fake | |
|---|---|---|---|---|
| 0 | 17366 | Merkel: Strong result for Austria's FPO 'big c... | German Chancellor Angela Merkel said on Monday... | 0 |
| 1 | 5634 | Trump says Pence will lead voter fraud panel | WEST PALM BEACH, Fla.President Donald Trump sa... | 0 |
| 2 | 17487 | JUST IN: SUSPECTED LEAKER and “Close Confidant... | On December 5, 2017, Circa s Sara Carter warne... | 1 |
| 3 | 12217 | Thyssenkrupp has offered help to Argentina ove... | Germany s Thyssenkrupp, has offered assistance... | 0 |
| 4 | 5535 | Trump say appeals court decision on travel ban... | President Donald Trump on Thursday called the ... | 0 |
Make a Dataset
make_dataset Funciton
This function does two things:
- Remove stopwords (such as “the,” “and,” or “but”) from the article text and title.
- Constructs and returns tf.data.Dataset with two inputs and one output. The input is in the form of (title, text), and the output consist only of the fake column.
def make_dataset(df):
stop_words = stopwords.words('english')
# remove stop words from titles and texts
df["title"] = df["title"].apply(lambda title: ' '.join([word for word in title.split() if word not in (stop_words)]))
df['text'] = df['text'].apply(lambda text: ' '.join([word for word in text.split() if word not in (stop_words)]))
dataset = tf.data.Dataset.from_tensor_slices((
# dictionary for input data
{"title": df[["title"]], "text": df[["text"]]},
# dictionary for output data
{ "fake": df["fake"]}
))
return dataset.batch(100) # batch the dataset
Split Dataset for Validation
spliting 20% of dataset to use for validation.
# Process data
df = make_dataset(raw_df)
df = df.shuffle(buffer_size = len(df))
# Split the dataset
train_size = int(0.8*len(df))
val_size = int(0.2*len(df))
train = df.take(train_size)
val = df.skip(train_size).take(val_size)
# Print Results
print("Train Size: ", len(train))
print("Validation Size: ", len(val))
Train Size: 180
Validation Size: 45
##Base Rate
labels_iterator= train.unbatch().map(lambda dict_title_text, label: label).as_numpy_iterator()
real = 0
fake = 0
for label in labels_iterator:
if label["fake"]==0: #if label is not fake, increase the count of the real
real +=1
else: #if label is fake, increase the count of the fake
fake +=1
print("Real: ", real)
print("Fake: ", fake)
Real: 8521
Fake: 9479
Our base rate (accuracy when a model makes only the same guess) prediction is somewhere around 50%
Text Vectorization
#preparing a text vectorization layer for tf model
size_vocabulary = 2000
def standardization(input_data):
lowercase = tf.strings.lower(input_data)
no_punctuation = tf.strings.regex_replace(lowercase,
'[%s]' % re.escape(string.punctuation),'')
return no_punctuation
title_vectorize_layer = TextVectorization(
standardize=standardization,
max_tokens=size_vocabulary, # only consider this many words
output_mode='int',
output_sequence_length=500)
title_vectorize_layer.adapt(train.map(lambda x, y: x["title"]))
Create Models
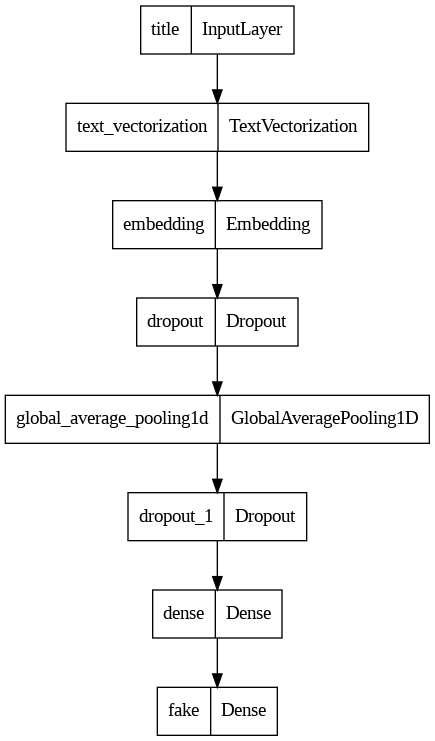
Using Functional API (rather than Sequential API)
First Model
Using titles to detect fake news
# Input Layer
titles_input = keras.Input(
shape = (1,),
name = "title",
dtype = "string"
)
# Hidden Layers
titles_features = title_vectorize_layer(titles_input)
titles_features = layers.Embedding(size_vocabulary, output_dim = 2, name = "embedding")(titles_features)
titles_features = layers.Dropout(0.2)(titles_features)
titles_features = layers.GlobalAveragePooling1D()(titles_features)
titles_features = layers.Dropout(0.2)(titles_features)
titles_features = layers.Dense(32)(titles_features)
# Output Layer
output = layers.Dense(2, name = "fake")(titles_features)
model1 = keras.Model(
inputs = titles_input,
outputs = output
)
keras.utils.plot_model(model1)
# compile model1
model1.compile(optimizer="adam",
loss = losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=["accuracy"])
# fit model1
history1 = model1.fit(train,
validation_data = val,
epochs = 20,
verbose = False)
/usr/local/lib/python3.10/dist-packages/keras/engine/functional.py:639: UserWarning: Input dict contained keys ['text'] which did not match any model input. They will be ignored by the model.
inputs = self._flatten_to_reference_inputs(inputs)
# Visualize Accuracy
plt.plot(history1.history["accuracy"], label = "training")
plt.plot(history1.history["val_accuracy"], label = "validation")
plt.legend()
<matplotlib.legend.Legend at 0x7f8a200e80a0>
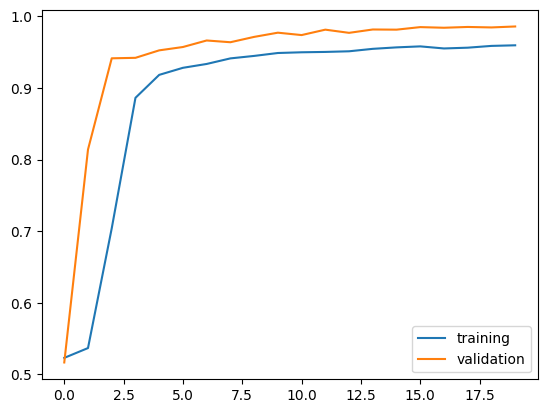
print("<Model 1 Final Accuracy: ", history1.history["val_accuracy"][-1])
<Model 1 Final Accuracy: 0.9857777953147888
Second Model
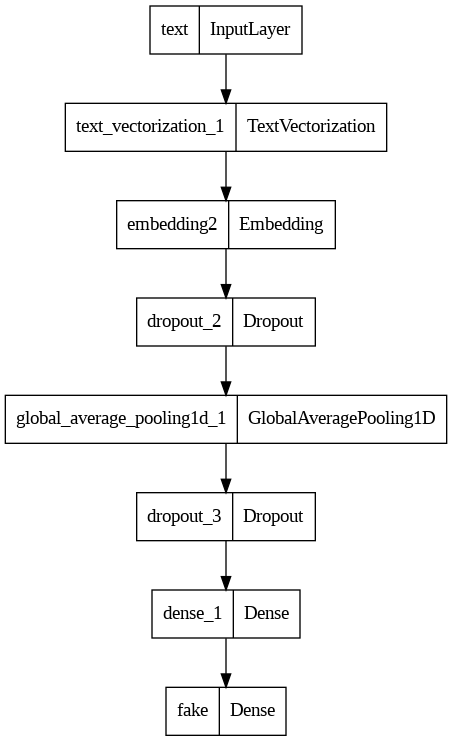
Using article text to detect fake news
# Text Vectorization Layer
text_vectorize_layer = TextVectorization(
standardize=standardization,
max_tokens=size_vocabulary, # only consider this many words
output_mode='int',
output_sequence_length=500)
text_vectorize_layer.adapt(train.map(lambda x, y: x["text"]))
# Input Layer
text_input = keras.Input(
shape = (1,),
name = "text",
dtype = "string"
)
# Hidden Layer
text_features = text_vectorize_layer(text_input)
text_features = layers.Embedding(size_vocabulary, output_dim = 2, name = "embedding2")(text_features)
text_features = layers.Dropout(0.2)(text_features)
text_features = layers.GlobalAveragePooling1D()(text_features)
text_features = layers.Dropout(0.2)(text_features)
text_features = layers.Dense(32, activation='relu')(text_features)
# Output layer
output = layers.Dense(2, name = "fake")(text_features)
# Create model2
model2 = keras.Model(
inputs = text_input,
outputs = output
)
# Visualize model2
keras.utils.plot_model(model2)
# Compile model2
model2.compile(optimizer="adam",
loss = losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=["accuracy"])
# Fit model2
history2 = model2.fit(train,
validation_data = val,
epochs = 20,
verbose = False)
/usr/local/lib/python3.10/dist-packages/keras/engine/functional.py:639: UserWarning: Input dict contained keys ['title'] which did not match any model input. They will be ignored by the model.
inputs = self._flatten_to_reference_inputs(inputs)
# Visualize Accuracy
plt.plot(history2.history["accuracy"], label = "training")
plt.plot(history2.history["val_accuracy"], label = "validation")
plt.legend()
<matplotlib.legend.Legend at 0x7f89a74064a0>
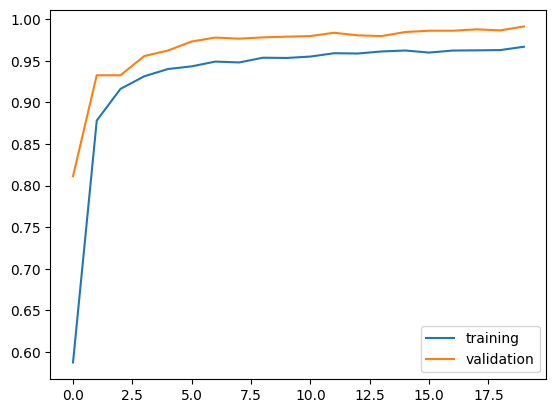
print("<Model 2 Final Accuracy: ", history2.history["val_accuracy"][-1])
<Model 2 Final Accuracy: 0.9913333058357239
Third Model
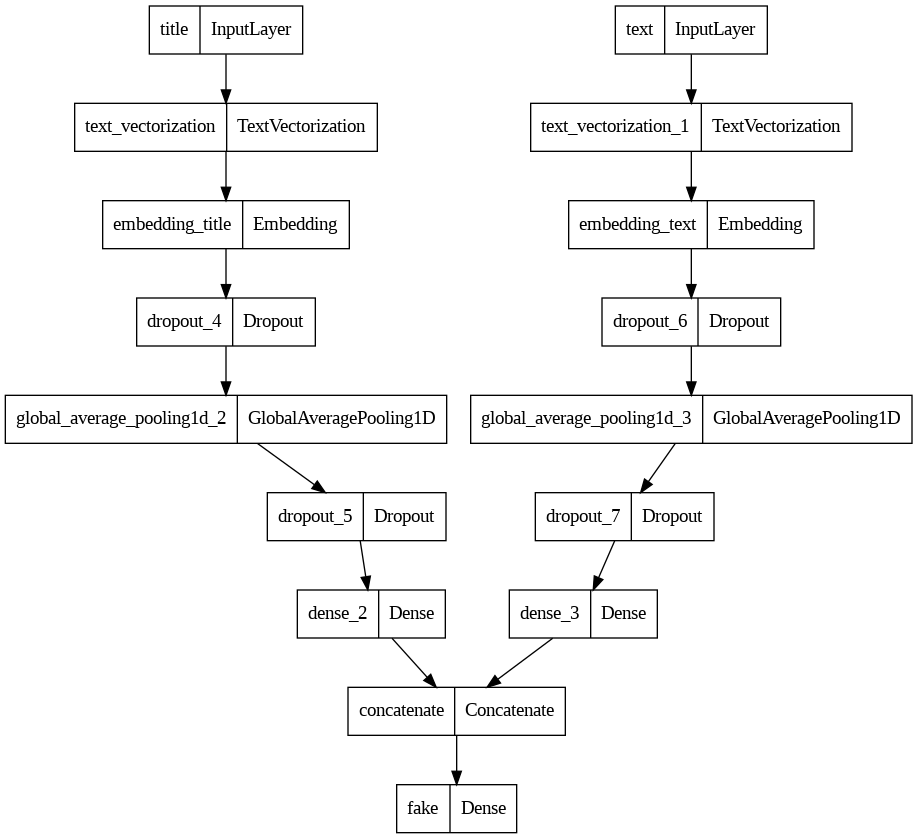
Using article titles & text to detect fake news
Two pipeline are same exact code from first two models
# First Pipeline
titles_features = title_vectorize_layer(titles_input)
titles_features = layers.Embedding(size_vocabulary, output_dim = 2, name = "embedding_title")(titles_features)
titles_features = layers.Dropout(0.2)(titles_features)
titles_features = layers.GlobalAveragePooling1D()(titles_features)
titles_features = layers.Dropout(0.2)(titles_features)
titles_features = layers.Dense(32)(titles_features)
# Second Pipeline
text_features = text_vectorize_layer(text_input)
text_features = layers.Embedding(size_vocabulary, output_dim = 2, name = "embedding_text")(text_features)
text_features = layers.Dropout(0.2)(text_features)
text_features = layers.GlobalAveragePooling1D()(text_features)
text_features = layers.Dropout(0.2)(text_features)
text_features = layers.Dense(32, activation='relu')(text_features)
# Concatonate Two Pipelines
main = layers.concatenate([titles_features, text_features], axis = 1)
# Output Layer
output=layers.Dense(2,name='fake')(main)
# Create model3
model3 = keras.Model(
inputs = [titles_input, text_input],
outputs = output
)
# Visualize model3
keras.utils.plot_model(model3)
# Compile model3
model3.compile(optimizer="adam",
loss = losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=["accuracy"])
# Fit model3
history3 = model3.fit(train,
validation_data = val,
epochs = 20,
verbose = False)
plt.plot(history3.history["accuracy"], label = "training")
plt.plot(history3.history["val_accuracy"], label = "validation")
plt.legend()
<matplotlib.legend.Legend at 0x7f89a512add0>
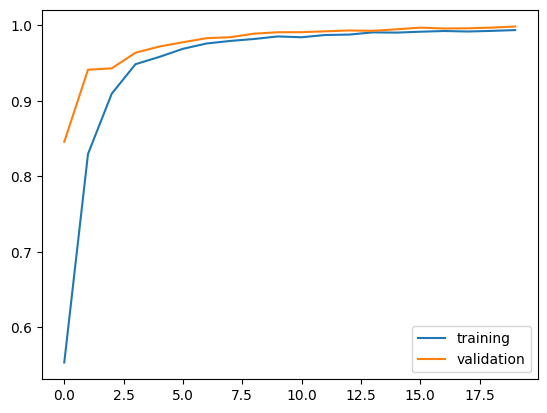
print("<Model 3 Final Accuracy: ", history3.history["val_accuracy"][-1])
<Model 3 Final Accuracy: 0.998651385307312
- Model 1 Final Accuracy: 0.987333357334137
- Model 2 Final Accuracy: 0.9877777695655823
- Model 3 Final Accuracy: 0.9973333477973938
Based on three models’ performances, it is best to use both title and text upon detecting fake news.
Model Evaluation
# Download & Process Test Data
test_url = "https://github.com/PhilChodrow/PIC16b/blob/master/datasets/fake_news_test.csv?raw=true" #test data
test_data = pd.read_csv(test_url)
test_data = make_dataset(test_data)
# Print Model Performance
print(model3.evaluate(test_data))
225/225 [==============================] - 2s 9ms/step - loss: 0.0191 - accuracy: 0.9947
[0.019058916717767715, 0.9946991205215454]
The final model got 99.5% accuracy.
Meaning, that the model will detect the fake news 99.5% of the time
Embedding Visualization
looking at the embedding learned by our model
Using 2D embedding
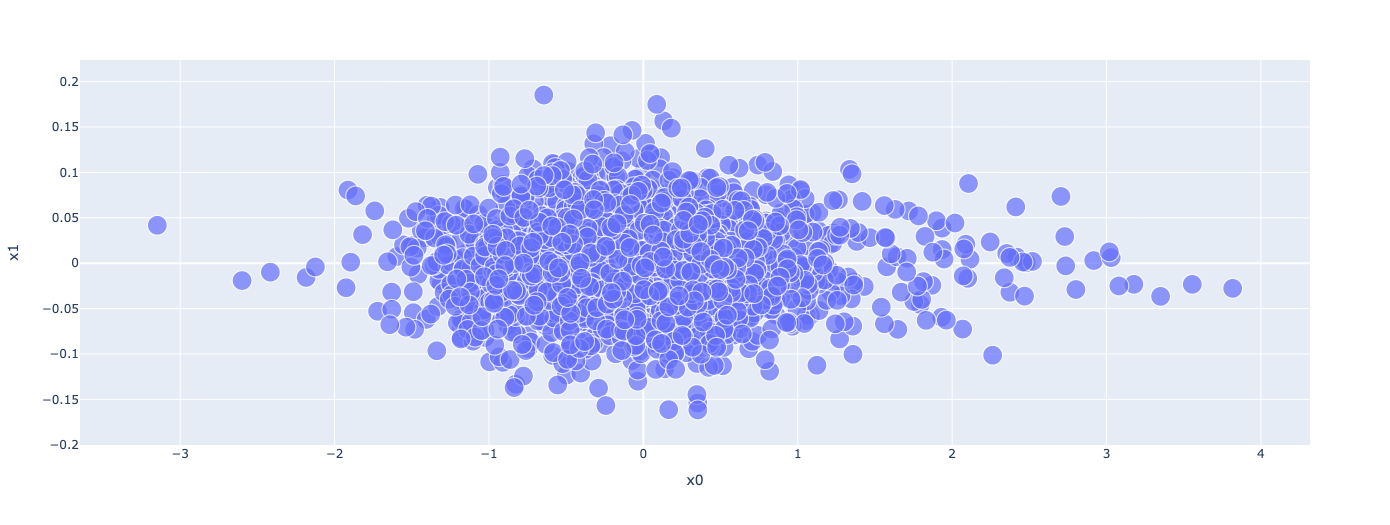
embedding_title Visualization
weights = model3.get_layer("embedding_title").get_weights()[0] # get the weights from the embedding layer
vocab = title_vectorize_layer.get_vocabulary() # get the vocabulary from our data prep for later
#Reducing to 2D dimension
pca = PCA(n_components=2)
weights = pca.fit_transform(weights)
embedding_df = pd.DataFrame({
'word': vocab,
'x0':weights[:, 0],
'x1':weights[:, 1]
})
# Plot Embedding Layer
fig = px.scatter(embedding_df,
x = "x0",
y = "x1",
size=[2]*len(embedding_df),
hover_name = "word")
fig.show()
embedding_text Visualization
weights = model3.get_layer("embedding_text").get_weights()[0] # get the weights from the embedding layer
vocab = title_vectorize_layer.get_vocabulary() # get the vocabulary from our data prep for later
#Reducing to 2D dimension
pca = PCA(n_components=2)
weights = pca.fit_transform(weights)
embedding_df = pd.DataFrame({
'word': vocab,
'x0':weights[:, 0],
'x1':weights[:, 1]
})
# Plot Embedding Layer
fig = px.scatter(embedding_df,
x = "x0",
y = "x1",
size=[2]*len(embedding_df),
hover_name = "word")
fig.show()
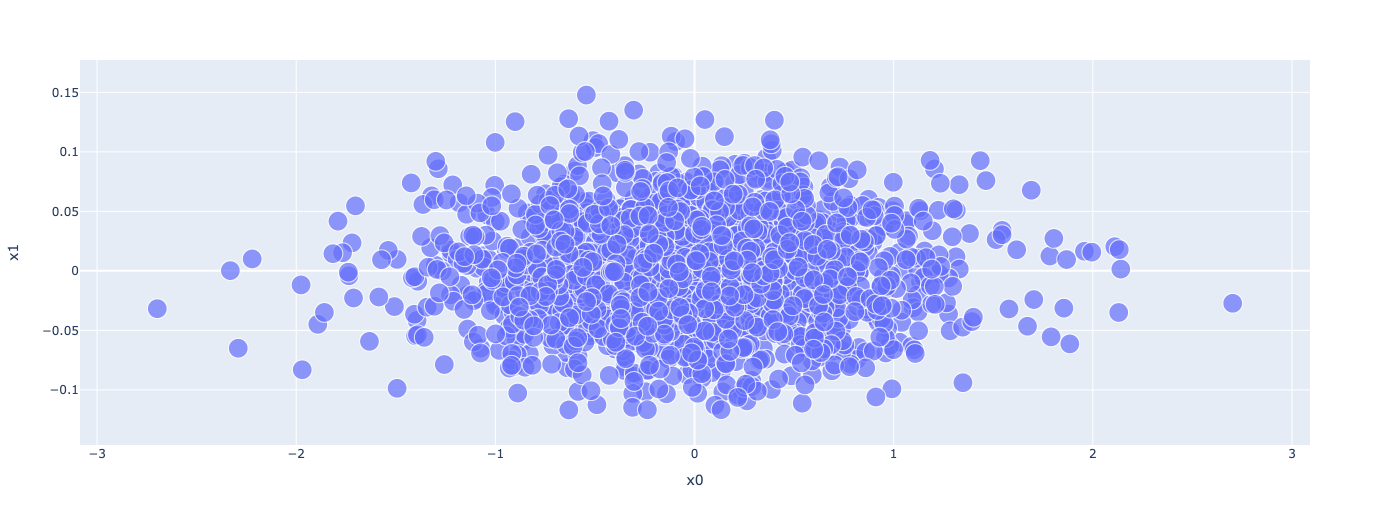
Embedding layer exposes minor detials of fake news that are not identifiable with normal human’s understanding. For example, “trumps” is highly correlated with fake news, but “trump’s” is highly correlated with real news. These minor differences are hard to notice but we can see from embedding visualization that our model is taking advantage of it.
Leave a comment